Other-区块链 RAFT协议详解
[TOC]
基于RAFT共同机制的用于维护分布式系统中解决分布式储存和共识机制的协议算法。
RAFT包括三种节点:leader、follower、candidate
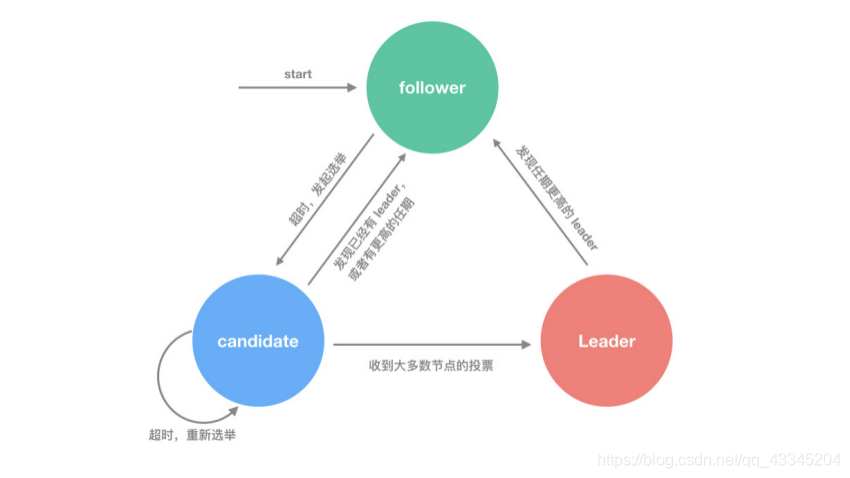
RAFT协议算法中包括三个基本组件动作,
-
Leader Election,用来模拟在每次联盟链上选出当前的Leader的操作,即向其他的follower发布并传递请求:在图中的表示形式是每个节点处于follower状态,并自动转化为candidate,然后对自己投票,并发起RequestVoteRPC,随后等待联盟链上的其他节点的回应:

- 当前节点获得超过半数节点的投票,赢得选举成为Leader,此时该节点所代表的联盟链上的成员可以对其他follower进行指示,可以进行相应的操作。
- 如果参加选举的节点有多个,也即在有多个成员申请修改链上内容的权限:如果其他节点赢得选举,该节点成为Leader,当前节点接收到对方心跳 ,当前节点变为follower。
- 选举超时,没有节点赢得选举,当前节点自增任期,重新发起选举:所有申请修改的成员都没有得到响应成功,要重新申请,只到结果呈现为情况1、情况2.
-
Normal Operation(basic log replication),用来每次client给每个节点发送请求的过程,每次请求就是一个指令,用来模拟在联盟链中每一个节点需要做的操作。
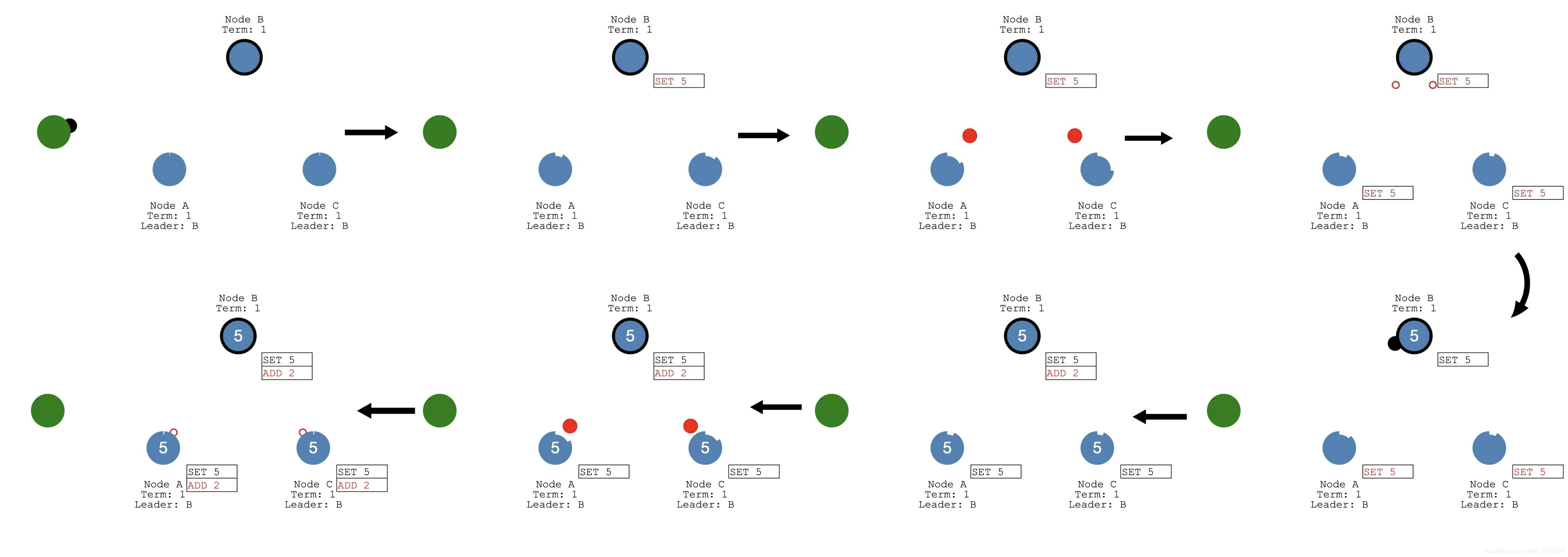
- leader接受请求后,把指令(Entry)追加到leader的操作日志中,然后对follower发起AppendEntries操作,尝试让操作指令(Entry)追加到Followers的操作日志中。如果有Follower不可用,则一直尝试
- 一旦Leader接受到多数(Quorums)Follower的回应,Leader就会进行commit操作,每一台节点服务器会把操作指令交给状态机处理。这样就保证了各节点的状态的一致性
- 各服务器状态机处理完成之后,Leader将结果返回给Client。
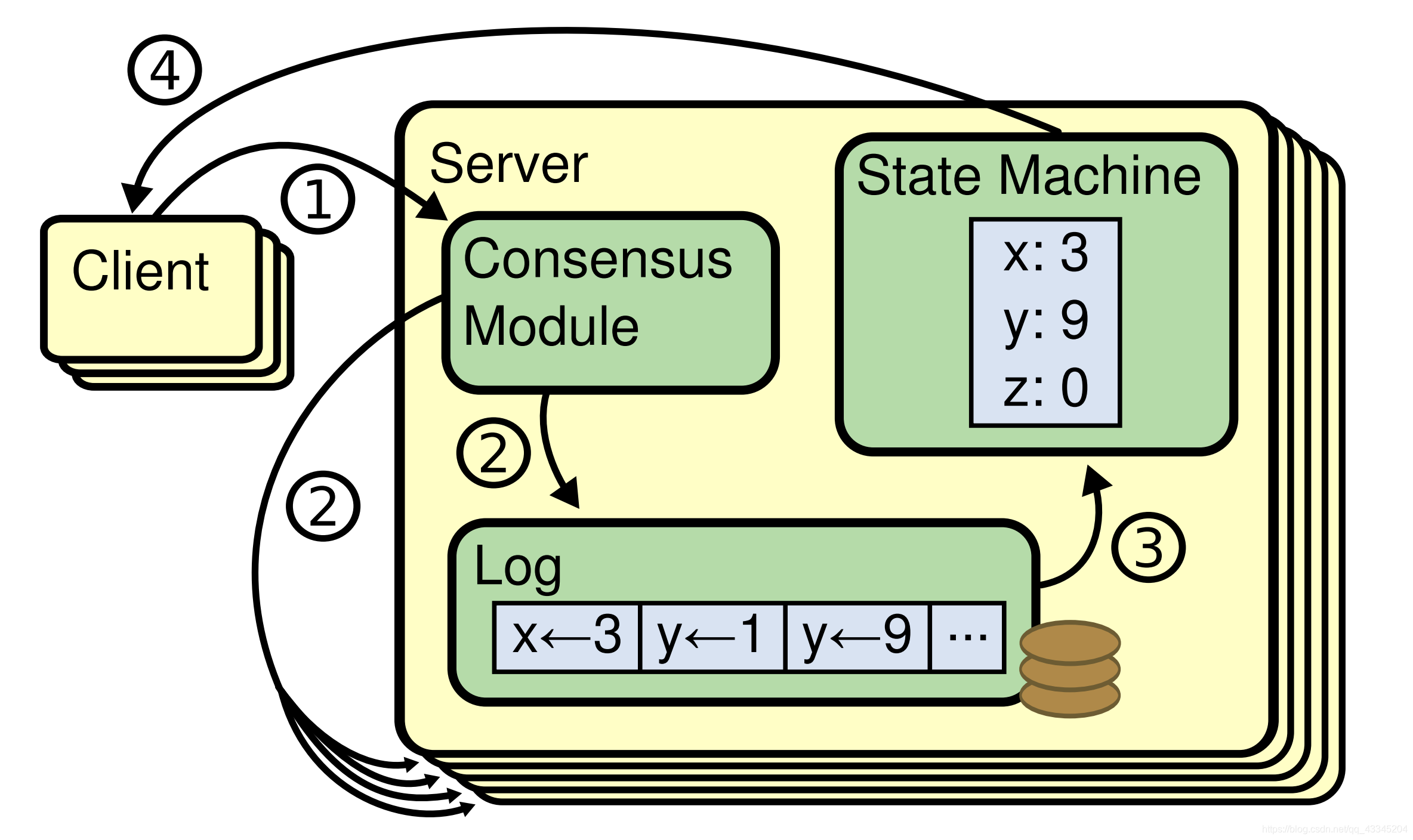
-
在这里插入图片描述
- 对于Normal Operation中的特殊情况例如发生了网络分区,RAFT同样可以以较高的容错性解决该情况,由于部分节点的心跳跳动周期之后没有leader的响应,节点认定为 leader down ,然后重新选举,这是产生双网络之后,有两个client分别为两个leader传达命令,在此情况下两个网络中的节点会有两种不同的指令,但是当修复网络分区之后,两个leader会通过查看期限,最终会统一为一个leader,使整个网络还是保持一致性。
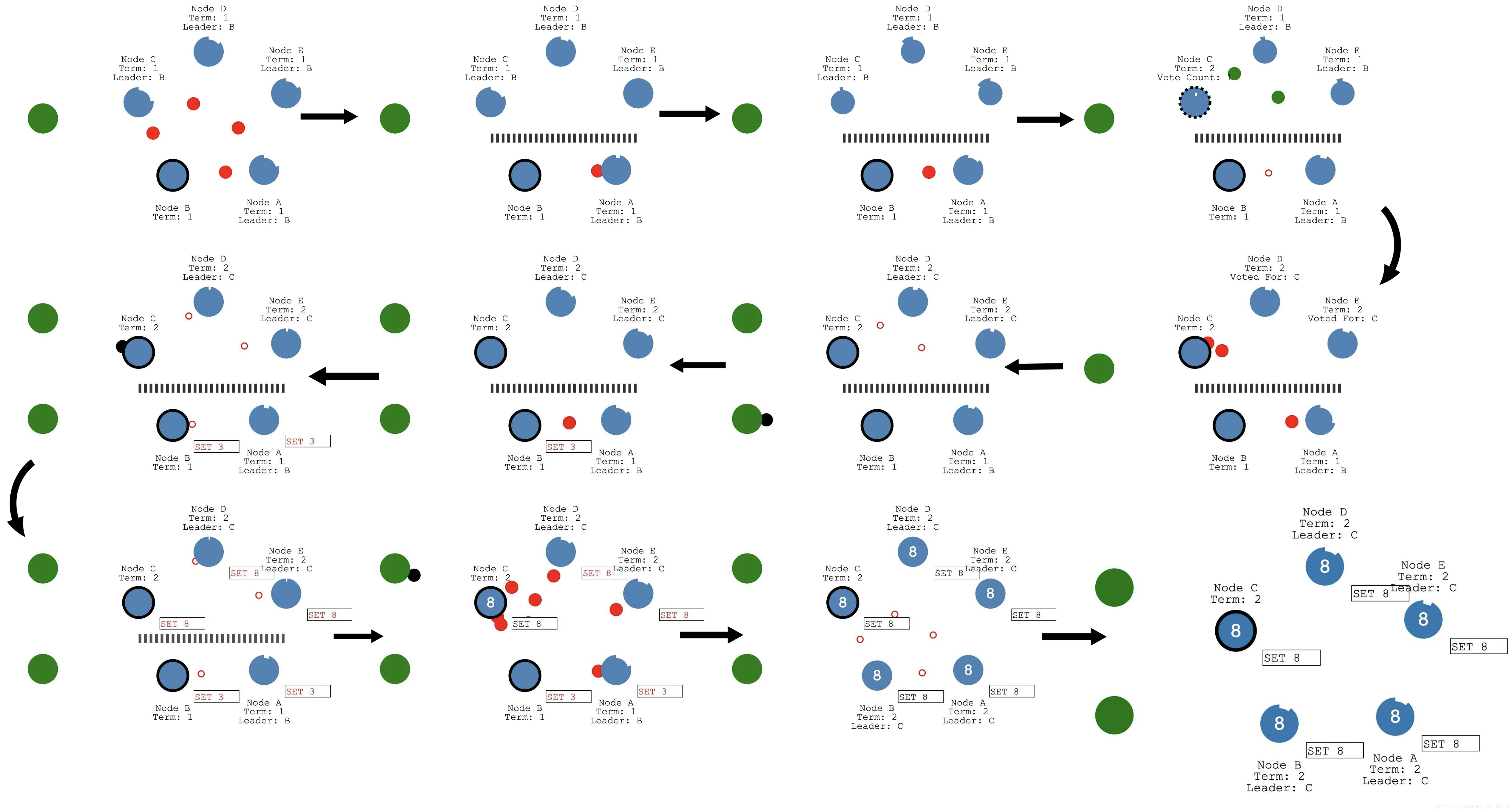
- 对于Normal Operation中的特殊情况例如发生了网络分区,RAFT同样可以以较高的容错性解决该情况,由于部分节点的心跳跳动周期之后没有leader的响应,节点认定为 leader down ,然后重新选举,这是产生双网络之后,有两个client分别为两个leader传达命令,在此情况下两个网络中的节点会有两种不同的指令,但是当修复网络分区之后,两个leader会通过查看期限,最终会统一为一个leader,使整个网络还是保持一致性。
-
Safety
- Election safety: 在一个term下,最多只有一个Leader:也即在联盟链中,在没有网络分区的情况下,最多只有一个leader;如果出现了网络分区的情况,则会执行Normal Operation中的特殊情况的执行方法。
- Leader Append-Only: 一个Leader只能追加新的entries,不能重写和删除entries
- Log Matching: 集群中各个节点的log都是相同一致的
- Leader Completeness:如果一个log entry被committed了,则这个entry一定会出现在Leader的log里,即leader会一致同步所有follower的信息。
- State Machine Safety: 如果一个节点服务器的state machine执行了一个某个log entry命令,则其他节点服务器,也会执行这个log entry命令,不会再执行其他命令。
Excerpt from http://thesecretlivesofdata.com/raft Experpt from In Search of an Understandable Consensus Algorithm